How much failure demand and rework do you feel is appropriate in your system?
Rework in software is the correction of unacceptable code. That doesn't include refactoring, which corrects only the design and expression of ideas without changing what the code does. This is limited to "something does not work correctly and we can't let it be released."
So, we don't want any of that, right? It delays releases and costs money. It distracts developers from doing new feature work. It raises the costs of release. Clearly, this is a bad thing, right?
No. This is a less-obvious question than it first seems.
Obviously, nobody wants to have errors and failures in their system. We would like to see 100% success rates, right?
Well, hold on...
Pass Rates
How would you feel if your QA/QC department did not report a single defect in the past 3 quarters? Not one!
What if all the code reviews passed with "Looks good. Nice work!" and nothing was ever returned for repair?
What if none of the security scans or linters ever reported a problem?
What if every one of your releases went out flawlessly and nobody ever reverted anything?
Would you actually be happy?
Would you be angry with code reviewers, testers, and your investment in scanners?
No Rejections? That's incredible!
The word incredible means that it has no credibility -- it's not trustworthy and likely untrue.
The problem with my phrasing above is that I expressed it as people not reporting problems, rather than expressing it as people doing diligent and competent work and still not finding any problems because the code is so perfect.
It's hard for people in most programming groups to even imagine that code could not be full of easily-catchable issues (and probably some subtle ones that aren't easy to spot).
But this leaves us in a funny picture: we need the code to have problems in order to prove the value of the gauntlet of post-code checkers we have put in place. How else can we prove the efficacy of the system that keeps bugs from escaping into the wild?
Competition
The usual system pits developers against testers (human and otherwise) and requires there to be a certain level of rework. For every bit of code that passes 100% on the first try, we give a demerit to our testing gauntlet. For every time code is rejected by the system, we give a demerit to the programming staff.
Somebody has to lose for the system to remain stable.
When the code improves, the test gauntlet has to raise the bar until they can report more issues (however trivial) in order to prove the value of their system and the need for the salaries and subscriptions paid periodically.
That creates a reputation that programmers are ineffective and flawed. If they again improve, then it casts shade on the gauntlet operators again.
Isn't this "using blame and shame to create an upward spiral"?
Does it make a difference?
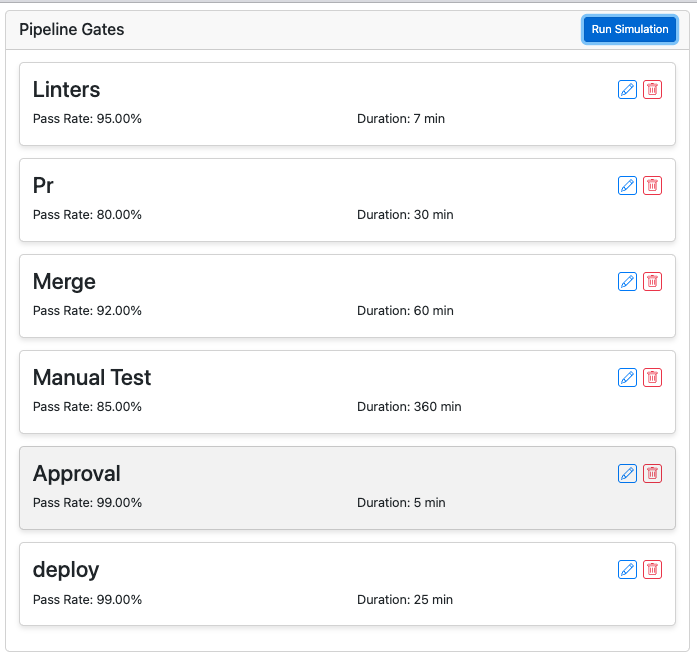
Here is a pipeline based on some factual post-code pipelines:
Looks pretty good, right? Pretty high pass rates?
The overall pass rate is only 58%.
Let's run some 100-task simulations. Ideally, each step would run once per task. When a code submission is rejected, it starts back over at the beginning.
The simulation is unfairly simple.
- It doesn't include time to remediate the problems.
- It doesn't consider queuing waits, such as when the QA is busy, and work piles up.
With this pipeline, 180 extra hours (rework) are needed just to operate the quality gates. That doesn't include programming or queuing time.
Costs
Intentionally driving down the pass rates (making the gates "extra tough") creates an appetite for rework and failure, and a kind of informal currency around it. One earns points for slowing the system, increasing the costs of work, delaying releases, and destroying the predictability of any work in progress.
What if we kept a high standard, and even raised the standard, but rather than using this to return work and raise costs, we focused on the developer experience and made it possible (possibly inevitable) that the developers would produce code that works and satisfies users?
Deming described the "quality control" function as "you burn the toast, and I'll scrape it" -- rework that costs money and time and cannot possibly be the path to total quality.
Shifting
The focus on "shift left" for QA is to move more of the evaluative function to moment of code creation.
This is wisdom.
There are many ways to approach development without rework.
With techniques like (proper use of) static typing and design-by-contract, we move more of the quality responsibility to compile time. Even dynamically-typed language often have a type-checking extension and these can make it hard to write ill-formed code witout knowing.
Most IDEs have some level of code-checking built into them. While some programmers are highly cognizant of warnings, errors, and suggestions there are many others who ignore these helpful quality reminders. Admittedly, not all warnings in all IDEs are useful, but that doesn't mean that they are all to be ignored.
There are a number of "lint" utilities that can be installed in the IDEs and editors we use. These can spot poor usage patterns, clumsy expressions, possible security flaws, anti-patterns and code smells, and unconventional formatting issues. Again, some developers refuse to install these and others ignore them.
Practices like TDD exist to provide a behavioral level of testing that goes beyond what a linter or IDE can check. With the microtests TDD relies upon, you don't just know that the function takes two integers and returns a floating point number; you can know that given a certain set of numbers, it will return the expected result. This is an extension of quality checking that has a lot of power: you can change how the code works provided it still does the right thing. This allows one to evolve the design and improve the expression of code ideas safely. It's one of the few ways of working that does (since DesignByContract is rarely implemented).
Automated testing helps here also. Using tools like Playwright and Storybook can take a UI development to a new level of reliability.
But the biggest left-shift seems to be one that people are in a huge hurry to discount - working together.
I'm not sure why a proven method of enabling CI/CD and high quality, lauded in many studies and publications (including the DORA report) seems to have such a curb appeal problem, but people don't want to think about this one.
It matters, though. Nobody knows all the grammar of all the programming languages they use every day. Nobody knows the entire standard library of any one of those languages, nor all the relevant standards. Nobody knows all of the application code. No one person can be expected to know and keep up with an application system and its ecosystem. A few people working together can get close enough, though. You might be amazed at the Venn diagram of who knows what and how little common space there is in solo programmers all "doing their own work." You would be amazed how much ground is covered by a diverse group of skilled workers.
But of course, if you don't have errors and rework so that all of your code goes out the door well and quickly and your customers aren't waiting and yelling at you then how can you tell which of your people are doing their best work?
And does that matter when your company is succeeding?